Music metadata: What it is and why it matters
A few weeks ago, I gave a lightning talk about music metadata. It’s one of my favorite niche topics to research, so talk covers a lot of what I know about music metadata.

Welcome to my talk about music metadata.

In this talk, I’ll cover what music metadata is, how it’s made (because it’s not discovered!) as well as what it’s used for — and why it matters. If you want to learn more, I’ll also talk about how you can interact with it.

Music metadata is crucial to the functioning of digital streaming platforms that we use every day.

Music metadata can be roughly categorized into three main types, as outlined by a 2011 patent from the Echo Nest, Automatically acquiring acoustic information about music:
- Acoustic metadata: the mathematical representation of the sound of a track
- Cultural metadata: text that describes the content
- Explicit metadata: the factual information about the track

Acoustic metadata is the “numerical or mathematical representation of the sound of a track”.
Some examples of acoustic metadata are things like duration. If you’ve ever explored the Spotify API, you might be familiar with other metadata fields like danceability, tempo, speechiness, or valence.
These example values are for SZA’s track Kill Bill (feat. Doja Cat):

Cultural metadata is “text-based information describing listener’s reactions to a track or song”.
Some examples of cultural metadata are things like genre tags that you might see on a SoundCloud track, names of playlists that the track is added to, tags added to the track in a service like Last.fm, hashtags on TikToks that sample audio from the track, even YouTube comments. It can also include things like album reviews, blog posts and comments about an artist or track.
I’d guess that the popular music blog aggregator the Hype Machine has probably been scraped to help build out cultural metadata examples. The examples on this slide are for Carly Rae Jepsen.

Explicit metadata is “factual or explicit information relating to music” — the things that you’re probably most familiar with and that you might immediately think of when you think of music metadata.
For example, the track name (Diamonds), artist name (Rihanna), including any featured artists as relevant, the release date (1 January 2012), as well as the C-line for copyright purposes (© 2012 The Island Def Jam Music Group) or the P-line to denote who owns publishing. The Sky Ferreira track “Nobody Asked Me (If I Was Okay) has a P-line of ℗ 2013 Capitol Records, LLC.
All of these examples are explicit metadata values that might be associated with a track.

You might be wondering about user behavior data? What about all my listening data that shows up in Spotify Wrapped or whatever?
That isn’t metadata about the music itself, but it is still relevant. And much like music metadata, the user behavior data that these platforms are collecting and defining are similarly opaque yet specific.
The combination of user behavior data and music metadata is what makes the other type of data valuable. For digital streaming platforms like Spotify, Apple Music, Tidal, Deezer, SoundCloud, and Pandora, having user behavior data to know that people are listening to music on the platform is useful.
But user behavior data is relevant for being able to develop categorization, clustering, and recommendation algorithms using the music metadata, which is extremely valuable. With the combination, you can calculate things like:
- Track duration before skipping
- Geographic region of listeners
- % of mainstream music listened to
- Track popularity among platform listeners
- Volume of repeat listens
- Number of playlist placements
- Likes and dislikes during radio playback
- User gestures like swipe
- Playback devices used
- Total monthly listeners
- Total minutes listened to an artist
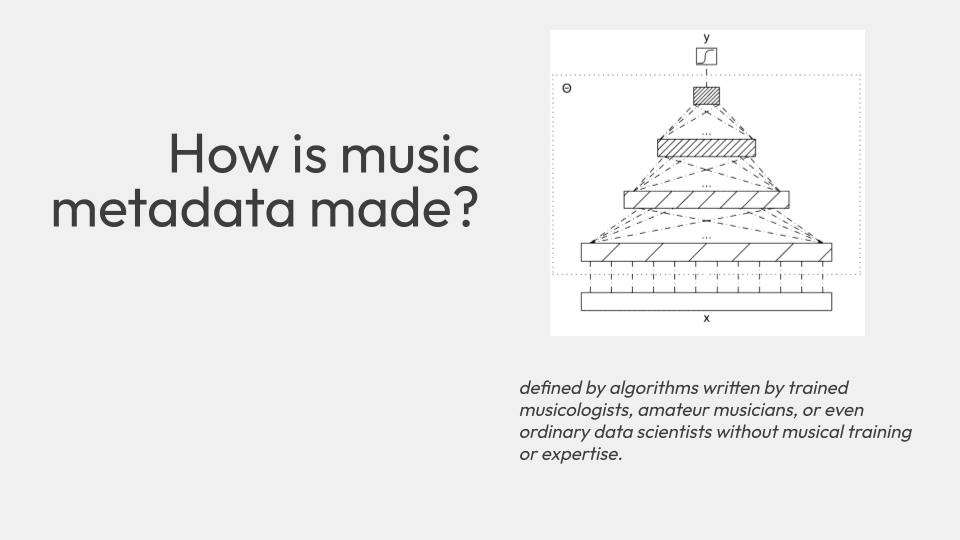
You might be wondering where music metadata comes from — and how it is made.
When I did research about this several years ago, I discovered that for the most part, music metadata is:
defined by algorithms written by trained musicologists, amateur musicians, or even ordinary data scientists without musical training or expertise.
Depending on the type of music metadata, there are different ways that the metadata might get made.

For acoustic metadata, manual annotation is the most relevant. If you’ve ever heard of the Music Genome Project from Pandora, that was expert musicologists, about 450 of them, at least in the beginning of Pandora, defining all sorts of metadata fields for music.
Nowadays, the manual annotation is more likely to be everyday data labelers performing something like human-in-the-loop quality assurance for tracks by emerging artists or in newly added regions, after being processed by algorithms and machine learning models.
After you have a manually annotated “ground truth” dataset, you can build algorithms and machine learning models to perform the labeling programmatically, using a split version of the manually annotated dataset as a way to both train models and test the outputs.
The algorithms and machine learning models are performing tasks like spectrogram analysis or audio fingerprint creation (part of how Shazam works, and also copyright detection like YouTube’s content ID), as well as analysis to derive acoustic metadata more generally.
For example, Spotify filed a patent for Automatic prediction of acoustic attributes from an audio signal, wherein they outline the attribution of more “subjective” acoustic metadata from a song:
While music is composed of objective properties (e.g., tempo, onsets, durations, pitches, instruments), its audio recording carries inherent information that induces emotional responses from humans, which are typically problematic to quantify. Subjective and lacking a base unit, like “seconds” for duration, or “hertz” for pitch, these responses may nevertheless be fairly consistent across the spectrum of listeners, and therefore can be considered intrinsic song attributes. Subjective attributes include for instance the measure of intensity or energy of a song, the valence or musical positiveness conveyed by the song, and the suitability of a song for a particular activity (e.g., dancing). Other song attributes, however, are reasonably objective but hardly detectable from the structure of the music, its score representation or its transcription. These include, for example, whether a song: was recorded live; was exclusively recorded with acoustic instruments; is exclusively instrumental; and the vocals are spoken words.
The patent, being a patent, goes on to detail the methods used to codify those subjective acoustic metadata values for a song into numeric terms, including the methods of collecting labeled audio content and the methods for predicting new values for unlabeled audio content.

Cultural metadata is also going to be manually annotated. The people performing the manual annotations for cultural metadata are oftentimes going to be slightly less expert data labelers. These days they’re usually performing quality assurance of machine learning categorization of tracks.
A lot of cultural metadata is also derived from what is published online about a track or an artist. The metadata comes from what people are saying in music blogs, forum discussions, public social media groups, or in the genre tags added to sites like Last.fm, even the hashtags used on a TikTok video or Instagram reel that uses the audio might be considered.
Anything that is on the public Internet can be scraped, cleaned up with a tool like Beautiful Soup, and then processed. Cultural metadata can be derived from the specific words or phrases used to describe a track, or even from the sentiment of language used—classic natural language processing tasks.
You are also contributing to cultural metadata. Surprise! All those playlists that you create on your favorite digital streaming platform, the names and descriptions of those are being collected and associated with the tracks in those playlists, and used to inform the cultural metadata for those tracks and artists.
The folks being paid to curate playlists for platforms like Spotify or Apple Music are also generating cultural metadata, categorizing tracks by mood, vibe, or genre based on the playlist they curate.
Other cultural metadata that everyday music listeners contribute includes comments that we leave on tracks on sites like YouTube or SoundCloud.

Explicit metadata, as you might expect, is mostly coming directly from the artists, publishers, and distributors themselves.
And surprise, that means it’s manually annotated. Interns (or better-paid roles) at the record labels perform the data entry to provide the explicit metadata, and content operations and quality assurance teams and the digital streaming platforms themselves review and update the metadata to make sure it’s correct.
The publishers and distributors of tracks also make sure that the explicit metadata is added or included when the track is distributed to streaming services, radio stations, and more.
The manual annotation and review process is important to make sure that the right songs show up in the right places in the streaming platforms, and to help prevent fraud and make sure the right people can get paid.
Some explicit metadata is added programmatically, like the unique IDs assigned by the streaming service (Spotify ID), a MusicBrainz identifier to associate the track with its unique metadata record in that dataset, or other programmatic IDs.

What is music metadata used for? You probably have some guesses. Honestly, music metadata is used for everything you might guess, but also more.

Like I mentioned earlier, there is a good amount of correlation with that user behavior data.
This is from the 2022 Spotify wrapped, where Spotify put together a sort of listening personality that was a little bit like, what if Myers-Briggs, but music?
My assigned personality was The Specialist, featuring the qualities of FNVU: Familiarity, Newness, Variety, and Uniqueness.
To derive a “personality” based on those characteristics, they had to use metadata like song release date, explicit metadata, as well as popularity, and for familiar to you versus unfamiliar to you, how frequently you listen to specific artists.
Those are pretty simple things to compute with a combination of user behavior data and pretty basic metadata. I even calculated it myself in 2022, essentially looking at the following questions:
- Does song age affect listen frequency?
- Do you listen on shuffle or to albums?
- Do you listen to popular music or obscure music?
- Do you listen to familiar artists more or less than new artists?
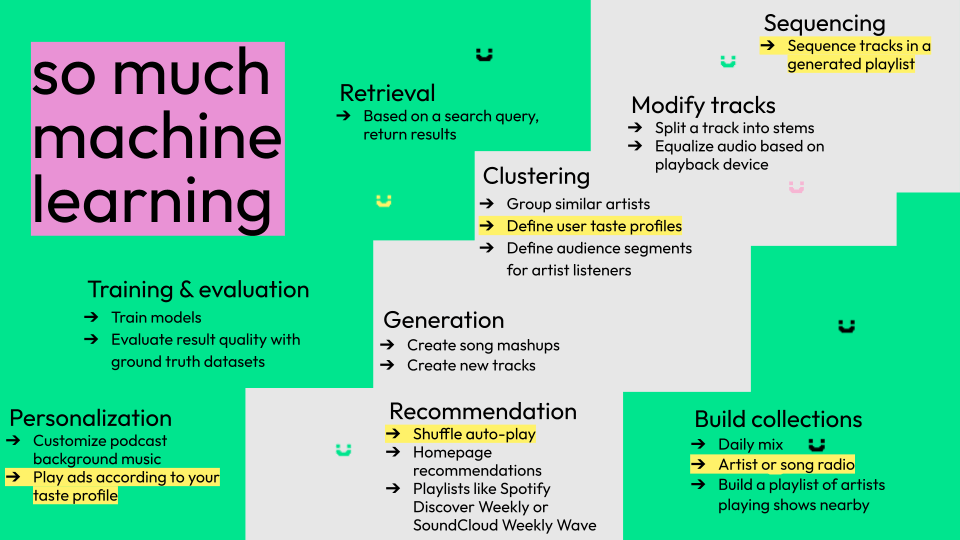
Music metadata is also used for so much machine learning. Machine learning is probably about 90% of what music metadata is used for.
Of this list, I highlighted some interesting use cases that you might guess, but also ones that you might not guess.
One example is playing ads to you according to your user taste profile that Spotify has defined according to your listening (plus metadata) so they can sneak ads in there where the sound and the music of the ad fits in with the music that you’ve been listening to, so that maybe you’re more likely to listen to the ad.
Music metadata and machine learning are also used for more typical tasks, like sequencing tracks, generating playlists, making recommendations, grouping similar artists, or modifying tracks to split them into stems or more simply equalizing audio playback.

Music metadata is also used for marketing. You’re probably familiar with Spotify Wrapped, Apple Music Replay, SoundCloud Playback, and more. But that’s also going to be a combination of that user behavior data and the metadata, the advertising I mentioned.
What is your listening personality? Your music evolution? Your audio day? Your streaming habits? Your musical aura?? The marketing wants you to wonder.
Music metadata is also used for advertising, whether for the example I mentioned earlier where ads are played with similar sounds as the music you’re listening to (helping make the ads more effective), or to recommend ads to you based on your user taste profile defined by the music that you listen to.
And music metadata is also provided back to artists and record labels (although usually only in aggregate metrics rather than raw data). Because they have amassed this enormous amount of user behavior data and the music metadata that they’ve created, digital streaming providers like Spotify can provide metrics on pages like Spotify for Artists.
Artists and their labels can then access metrics like “which playlists are your tracks being added to”, “which tracks are being streamed or saved to user’s libraries”, or “top cities where your listeners are streaming from” and then ostensibly use that data for their own marketing and promotion campaigns. Depending on the terms of various record label contracts, additional metrics might be available for a fee, but the contents of such contracts are not publicly available.

Metadata is also really important for calculating royalties. Different people who contribute to a track are entitled to different shares of the music royalties, depending on where the music is purchased or played.
- Publishers (who own the masters) own the rights to reproduce the work and distribute reproductions of the work.
- Performing artists (anyone who is credited with having performed on the track) are the named artist and featured artists listed on the track. If you’re not listed on the track, you don’t get paid for being a performer.
- Record labels are typically assigned the rights of performing artists in exchange for a record deal and an advance, so they’ll often be allocated the share that would ordinarily go to the performing artist(s).
- Songwriters (who wrote the lyrics, or is credited with having done so) are owed a negotiated portion of the publishing royalty.
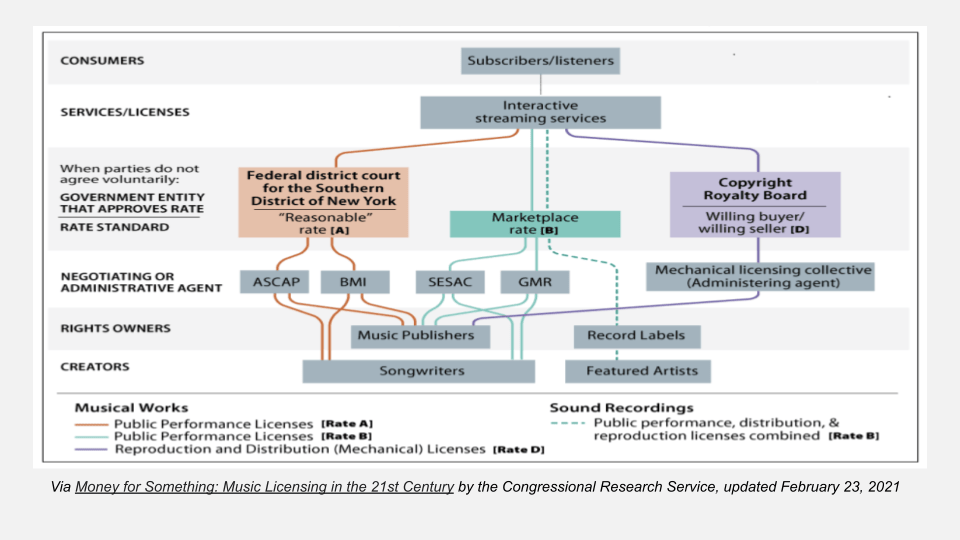
If you’re not familiar with music royalty calculation, this is one graph that represents one type of royalty that is collected. I think this one is specific to interactive streaming services (which are not all streaming services, just one type) published in Money for Something: Music Licensing in the 21st Century by the Congressional Research Service, updated February 23, 2021.
You can see highlighted in different colors the different types of rates that get paid out and the different places and people that they are paid out to. So, ASCAP and BMI are performing rights organizations in the United States, and they handle payouts to songwriters and music publishers primarily.
SESAC and GMR are performing rights organizations that make it easier to license music (especially internationally), so they handle the payouts from the international streaming services to the songwriters and music publishers, as well as the record labels and featured artists on the tracks.
Everyone gets a different cut according to their role on the track, and the role on the track is defined in that explicit metadata. So if that is wrong, stored somewhere weird, or duplicated, someone is not getting paid.

As you might guess, we’re in this new ~ * magical * ~ AI era, and as such, music metadata is also used to generate music.
Some example prompts that people might use that are going to reference specific acoustic, cultural, and explicit metadata fields could be things like generate a live track, so that’s going to use liveness, featuring trumpets, so that’s going to have to do with that instrumentalness.
Or make it 140 BPM, make it a pop song, make it the country song, but with trap beats… give me 2010s blog rock energy, similar prompts.
The only reason that prompt-based AI generation of music can work is because models have access to the cultural, acoustic, and explicit metadata that can correlate a description of a track with the mathematical representation that is stored digitally.

So, why does music metadata matter?
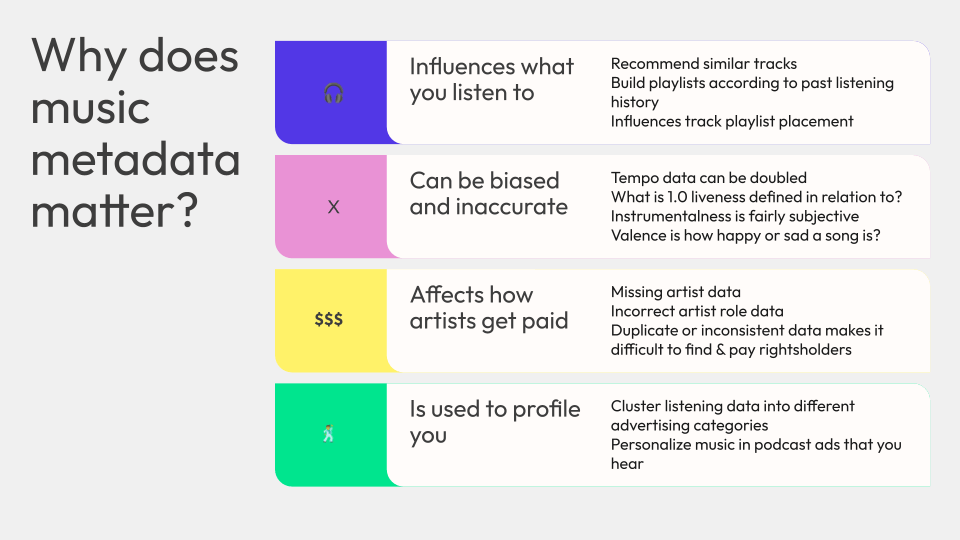
Music metadata directly influences what you listen to. The valence of track that you listen to (or many tracks) might be higher, indicating that you like happy music, so recommendation algorithms show you more music that is happy. Or similarly, if you listen to a bunch of sad-seeming music, you might get recommended more sad music (which might lead to you being sad for longer).
In addition to being used to recommend similar tracks to you, music metadata can influence track placement on playlists. If a popular playlist is generated by a machine learning pipeline, music metadata like genre (cultural) or bpm (acoustic) affects which tracks are selected for the playlist. Even if a human curator is in-the-loop, metadata characteristics can help narrow down the possible tracks to be included into an easily reviewed list.
Listening to recommendation playlists (like Spotify’s Discover Weekly or SoundCloud’s Weekly Wave) or curated playlists (like Spotify’s RapCaviar) drives music discovery and informs what you listen to, driving your music taste in a specific direction.
The more you listen to streaming services and rely on the playlists and recommendation algorithms, the more your music habits depend on music metadata.
The tracks included on curated playlists that you listen to drive your music discovery and music taste over time, directly influencing what you listen to.
Music metadata can also be fairly biased and inaccurate. I did a small research project last summer to review sped-up songs and identify, on average, how much they were sped up compared to their regular songs. Unfortunately, a lot of the tempo data was just totally inaccurate, which made such an analysis quite difficult. Tempo data is frequently doubled (or halved).
In addition, some acoustic metadata values like valence don’t have an objective baseline, which makes the accuracy of the metric difficult to evaluate. For that metric and others, they are likely defined in relation to something, but that relative definition is opaque. Other metadata values are inherently subjective, like instrumentalness. Even the Spotify API definition for the now-deprecated Get audio features for a track endpoint makes that subjectivity clear:
Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0.
Music metadata also directly affects how artists get paid, like I mentioned. If explicit metadata is missing, such as artist data, or if the role is inaccurate, or if there is duplicate or inconsistent data, it gets more difficult to identify and pay the rightsholders.
Metadata is also used to profile you in combination with your user behavior data of a given streaming service. Use cases like clustering listening data into different advertising categories, or specific tasks like personalizing music in the podcast ads that you hear.

If you remember nothing else, remember that the data labelers that are processing and tagging metadata are the tastemakers of the AI era. Data labelers directly control which playlists are being generated and which songs are being added to them, and that shapes what we listen to.
Andrej Karpathy, cofounder of OpenAI pointed out in a post on X that:
People have too inflated sense of what it means to “ask an AI” about something. The AI are language models trained basically by imitation on data from human labelers. Instead of the mysticism of “asking an AI”, think of it more as “asking the average data labeler” on the internet.
Data labelers create music metadata, that metadata is used to inform music streaming, and as such, your experience on a music streaming platform is effectively curated by data labelers.

So what do you do with this knowledge?
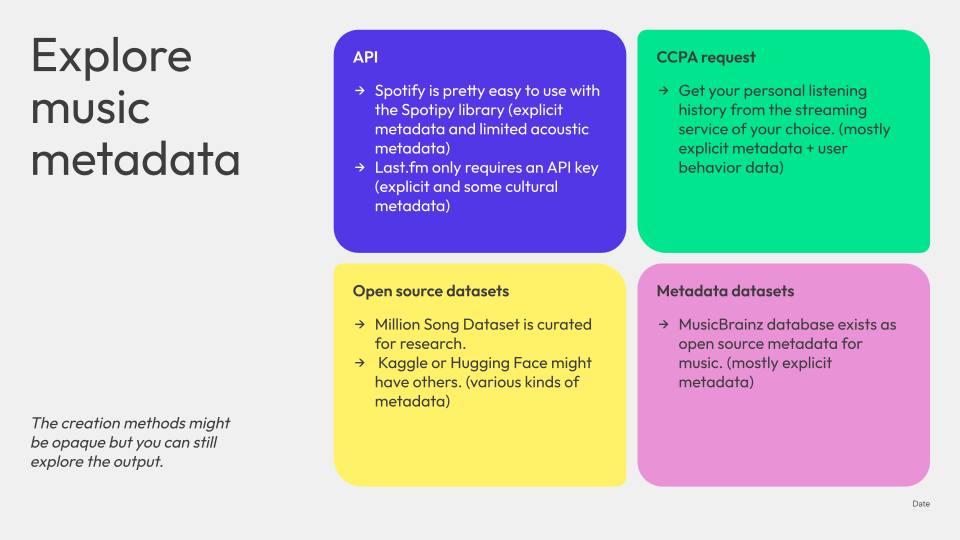
One thing you can do is explore the metadata yourself. Play around with it, discover what is cataloged and defined, assess its accuracy, and discover what it can and cannot tell you about music.
You can use a few different methods to retrieve music metadata:
- API
- CCPA request
- Open source datasets
- Metadata datasets
Spotify’s API is pretty easy to use with the Spotipy Python library in my experience, and you can get detailed explicit metadata, limited acoustic metadata, and some cultural metadata.
There aren’t that many ways to get acoustic metadata for free. Spotify recently deprecated their most interesting API endpoints and options for retrieving acoustic metadata: Get Track’s Audio Features and Get Track’s Audio Analysis, probably because they were being used to build machine learning models, although it’s interesting that Spotify only felt threatened enough to deprecate the API endpoints in late 2024.
From other Spotify API endpoints like Get Track for, you can get details like:
- Track name
- Album, album type, total number of tracks, album name, release date
- Artists on the track
- Track duration, whether the track has explicit lyrics
- Unique identifiers like the Spotify ID and external IDs for the track like ISRC or EAN
- Popularity of the track
For an endpoint like Get Artist, you can get details like:
- Artist name
- Total number of artist followers on Spotify
- Genres that the artist is associated with
- Spotify ID
- Popularity of the artist, calculated from the popularity of the artist’s tracks.
Mostly explicit and cultural metadata.
Another API endpoint, for the Last.fm API, only requires an API key for requests (no complicated OAuth flows). You can retrieve explicit metadata and some cultural metadata from Last.fm, but no acoustic metadata.
For example, for an endpoint like track.getInfo, you can get details like:
- Track name
- Track duration
- Total number of track listeners and total play count for the track
- Artist name and album name for the track
- MusicBrainz Identifiers for the track, artist, and album
- Top tags for the track, but what makes a tag “top” is not defined by Last.fm beyond mentioning that they are “ordered by tag count”.
For more details about the tags assigned a given track, you can call the track.getTopTags endpoint and retrieve:
- Number of tags for a tag
- Tag name (like “hard rock”, “rock”, classic rock” for AC/DC)
- URL for the tag (where you can view top artists, tracks, albums, and related tags for the tag)
For an endpoint like artist.getInfo, you can get details like:
- Artist name
- Total listeners and plays (play count) for the artist
- Similar artists
- Tags for the artist
- Bio details for the artist
If you use Last.fm (like I do), you can also retrieve your own user behavioral data (listening behavior) as recorded by the various systems that you use to record listening activity and send it to Last.fm. I mention that caveat because what counts as a “listen” can vary across systems, which can affect the accuracy of the collected data.
Beyond simple programmatic methods of collecting your own music metadatasets, you can also request additional data. If you’re in the United States and a California resident, or live in a European country subject to GDPR, you can usually make a data request of specific services.
For example, I’ve made a CCPA request in the past to request my Shazam history for every single song that I’ve Shazammed. You get a history of your user behavior in the Shazam app and service generally, but also a CSV-formatted file containing a record of your synced Shazam results — artist, title, and date (although if you allow Shazam to use location services, you might also get the longitude and latitude where you Shazammed the track).
Beyond these methods, you can access an open source dataset or another metadata dataset. The MusicBrainz identifier output in the response of most Last.fm API requests aligns with the MusicBrainz Database, which functions as an publicly available database of music metadata.
Other datasets are those like the Million Song Dataset, primarily created for research purposes, but which contains acoustic, cultural, explicit metadata. Beyond that one, Kaggle and Hugging Face offer hundreds (if not thousands) of other datasets to choose from.
The creation methods of music metadata might be opaque but you can still explore the output.
Some questions I was asked include:
What is your personal favorite piece of musical metadata, and how have you used it?
Tempo is probably the one I’ve spent the most time with, in attempting to analyze the difference in bpm for sped-up songs and the original versions. However, that project ended up being mostly an exercise in data cleaning, so it wasn’t nearly as exciting as I hoped it would be.
Maybe the funniest piece of metadata is valence, because it is sort of just like, “what if we put a number on how happy this song sounds?”, which like, okay sure, that’s a thing you can do.
I mostly care about, like, the accuracy of the metadata and how arbitrary it is to measure some of these qualities that we made into math and made them feel objective, but they are mostly subjective.
How does the emergence of new genres work? Like, sped up is, like, a thing that people talk about in the past couple years, but my understanding is, like, early 2000s, we call it, like, Nitecore, or, like, meme rap is a thing, but it’s only popularized in the past 10 years, and all that.
That’s where the cultural metadata is coming from, where it’s like, maybe someone mentions it on a blog, people start to recognize patterns and themes in the data that they’re scraping and encode it in the cultural metadata that gets built.
There’s also a certain element of, like, Spotify just makes stuff up. Like, Spotify might notice patterns or trends in terms of clusters of artists, and then they’ll decide “this is a micro-genre”, and they can get really weird sometimes. Spotify used to return more of these in the official “genres” array returned for the Get Artist API, but now I think they keep those internally and the exposed ones are a lot more standardized.
In your own self-evaluation, how much did recommendations affect your music taste over time?
To be honest, not that much I don’t think? Nowadays I actively fight against it. I’ve been largely reducing my Spotify usage, and I pretty much buy all of my music on Bandcamp and listen to it just on my phone and make my own playlists. For more details about how I discover music, check out my post My evolving music discovery pipeline.