Will we see prompt-based music generation?
Image generation tools like DALL-E 2, Midjourney or interfaces built on top of Stable Diffusion have gained a lot of popularity, both due to the quality of images created and the novelty of transforming text input into a visual output.
The other aspect of their popularity is that these tools let people without art or design training use text to describe what they want to see, and then (hopefully) get some images that resemble what they imagined.
It seems like an effortless way to avoid paying artists for stock photography, custom illustrations, and other work. Already, Shutterstock has integrated DALL-E 2 into its service, and so has Microsoft.
Artists are now in competition with prompt-based image generators. Will musicians soon be competing with prompt-based music generators? Is it worth the effort to try to replace musicians?1
Why generate music? #
Music is everywhere, even where you don’t actively think about it.
Short clips of music appear in news broadcasts between segments, as podcast intros, outros, and background music.
Instagram reels and TikToks also feature short clips of music, as do transitions between scenes in a sitcom.
Longer clips of music show up as the background music for an explanatory YouTube video, or even as a television or film soundtrack. Most restaurants, office buildings, and even shopping malls play music continuously. My office even plays music in the bathrooms.

Technically, all of that music needs to be licensed. Licensing music costs money.
If you could generate music using machine learning, you could create royalty-free music for any or all of these use cases. No licenses, no payments. A prompt-based music generator could make it easy for anyone to create that music.
Is anyone building a prompt-based music generator? Does one already exist? It’s complicated.
A brief summary of existing music generation tools #
Music generation is far from a new idea, even using machine learning. However, most music generation tools use audio as the input, or prompt.
Audio clips as prompts #
In April 2020, OpenAI released Jukebox, which:
“generates music, including rudimentary singing, as raw audio in a variety of genres and artist styles.”
However, Jukebox doesn’t use a prompt-based interface.
The same organization that created Stable Diffusion, Stability AI, is working on audio generation next with HarmonAI. So far, they have a tool called Dance Diffusion which requires you to train a model on music that you want to generate more of. A contributor named Markov Pavlov created a guide on How To Train Dance Diffusion AI To Generate Sounds.
HarmonAI has a Google Colab notebook linked on their GitHub profile that includes guidance for generating random samples, regenerating your own sounds, and interpolating between two sounds. HarmonAI seems to be taking a similar approach to Stable Diffusion with Dance Diffusion by releasing the model framework and leaving any sort of prompting functionality or user interface to be built by others.
Spotify released a tool in June 2022 called Basic Pitch which takes audio input and outputs the same audio transcribed in MIDI format. This isn’t a music generation tool itself, but the author of the blog post introducing Basic Pitch works on music creation research at Spotify, indicating that this work could be a stepping stone for actual music generation based on audio input.
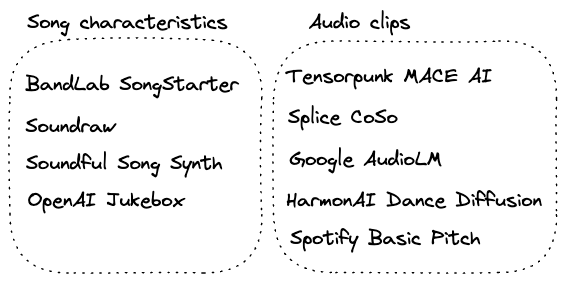
As for other organizations in this space, in early September 2022, GoogleML released a tool called AudioLM, modeled after large language models like GPT-3. AudioLM works by supplying a few seconds of audio as a prompt, then the model continues the audio based on the prompt.
This is one step closer to a prompt-based music generator, in that it uses a prompt to generate responses, but in using audio to generate audio, it lacks the cross-media generation in use by image generation models like DALL-E 2 and Stable Diffusion, which use text prompts to produce images.
Beyond releasing AudioLM, Google Research also supports the Magenta Team, which “is an open source research project exploring the role of machine learning as a tool in the creative process.”
Song characteristics as prompts #
Using machine learning as a tool for music creation or music production is popular. Many new businesses are gaining traction by offering various machine-learning-based generation services, such as Soundful, profiled in an interview on Music Business Worldwide; SoundDraw, Starmony; BandLab’s SongStarter; Splice’s CoSo and others.
All of those businesses share a common prompt approach, in that they let users of the service specify song characteristics like genre, mood, tempo, and more to prompt the music generator.
Other companies that work on creating generated music, such as Jukedeck, have already been acquired. Jukedeck was acquired by TikTok parent company ByteDance, and I couldn’t find any information about how it works.
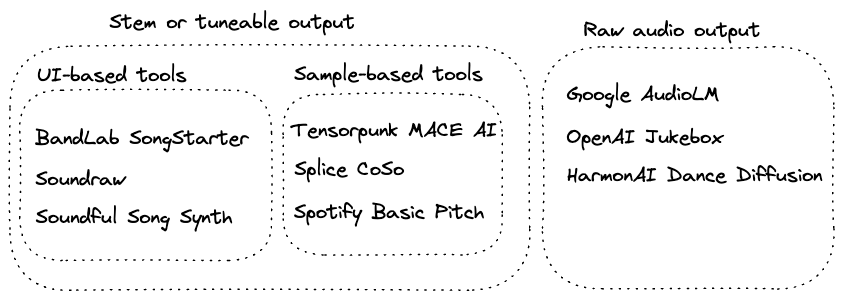
Beyond these recent companies and tools, there have been looping tools and samples available to assist music production as long as synthesizers and music production software have been around.
Ryan Broderick’s experience using a tool called MACE, which “utilizes the power of machine learning and artificial intelligence to generate new samples as defined by categorized model’s [sic].”, led him to comment in a recent issue of his email newsletter Garbage Day:
I think we’re getting closer every day to a fully-functional DALL-E-like tool that can handle at least parts of the music production or songwriting process.
There are a lot of options to generate music using machine learning and artificial intelligence, and this overview barely covers what’s available. However, none of these tools support text prompts to generate audio and music. Why is that?
Probably because it’s hard enough to generate music at all.
Music generation is hard #
Music is more than just sound. Music has component parts, like lyrics, a melody, a harmony, a bassline, a drum track, and all of those need to be pitched in the same key, at the same tempo—and sometimes change key and/or tempo within the song.
While it’s possible to write an algorithm to generate a specific type of music, if you want to generate any type of music or audio based on an arbitrary input, that is where you need machine learning—more than just one algorithm.
An article from 2020, A Comprehensive Survey on Deep Music Generation: Multi-level Representations, Algorithms, Evaluations, and Future Directions lays out 3 levels of music generation:
score generation produces scores, performance generation adds performance characteristics to the scores, and audio generation converts scores with performance characteristics into audio by assigning timbre or generates music in audio format directly.
Let’s break down that third level of music generation, audio generation, into more granular levels. I think the levels for generating good music are something like the following:
- Generate a single instrument melody.
- Generate a dual instrument melody and harmony.
- Generate 15–30 seconds of multiple instruments, with a melody, harmony, and rhythm.
- Generate 2 minutes of multiple instruments with a melody, harmony, rhythm, and an actual song structure.
- Generate the same with vocals.
- Generate the same with vocals singing actual words.
I think the most difficult challenges in making it through all those levels are the following:
- generating a melody, harmony, and rhythm that complemented each other.
- generating that, but in a song structure like “verse, chorus, verse, bridge, chorus, verse”.
- generating that, while adding coherent vocals and lyrics.
When it comes to the machine learning techniques that you need to tackle those levels, OpenAI’s blog post introducing Jukebox goes into some detail in the Motivation and Prior Work section.
To paraphrase that section of the blog post, there are a number of ways to generate music and those depend on how you computationally represent the music:
- Symbolic generators require you to “specif[y] the timing, pitch, velocity, and instrument of each note to be played”, representing the music as those specific elements.
- Raw audio encoding requires breaking music down into individual “timesteps” to represent each different type of audio in a track. As OpenAI points out, “A typical 4-minute song at CD quality (44 kHz, 16-bit) has over 10 million timesteps” due to the complexity and length of music audio.
- You could also combine those two approaches.
Beyond those options outlined by OpenAI, you could also use a diffusion model, as described in the NVIDIA blog post, Improving Diffusion Models as an Alternative To GANs, Part 12.
Even after you decide which approach to take to generate music, then there are the limitations of the generated audio to contend with. OpenAI’s blog post about Jukebox covers the limitations they encountered:
while the generated songs show local musical coherence, follow traditional chord patterns, and can even feature impressive solos, we do not hear familiar larger musical structures such as choruses that repeat.
Ultimately, these challenges and limitations exist because while machine learning (ML) researchers talk about “teaching” models, and developing models capable of “self-supervised learning”, it’s tough to figure out what the models are actually “learning”.
Are generative and diffusion models capable of emulating song structure? Song structure doesn’t seem to be explicitly encoded in common audio feature datasets, but there is likely enough information in the datasets to interpret it, with a change in key, tempo, energy, or other feature combinations. It’s another challenge for generating music.
Music generation is hard. Generating music based on an arbitrary text input is harder. But let’s dig into the imaginary nuts and bolts. What would you need to make a prompt-based music generator?
What’s needed to build a prompt-based music generator? #
First, you’d need a lot of high-quality data. Specifically, you’d need the following:
- A large database of music that encompasses a wide range of genres and styles.
- A large amount of metadata about that music, describing the characteristics of the music in quantitative terms that can be algorithmically modeled.
- A large amount of text that describes characteristics of the music, that can be mapped to the quantitative characteristics.

You need the music itself so that you can identify the relevant metadata needed to train a machine learning model, or even to train a model by playing the music itself.
You need the metadata because you need to provide a quantitative representation of the audio and musical characteristics of a track. If the characteristics are stored as quantitative metrics, they can be manipulated by algorithms and used to train a generative machine learning model, or network of models.
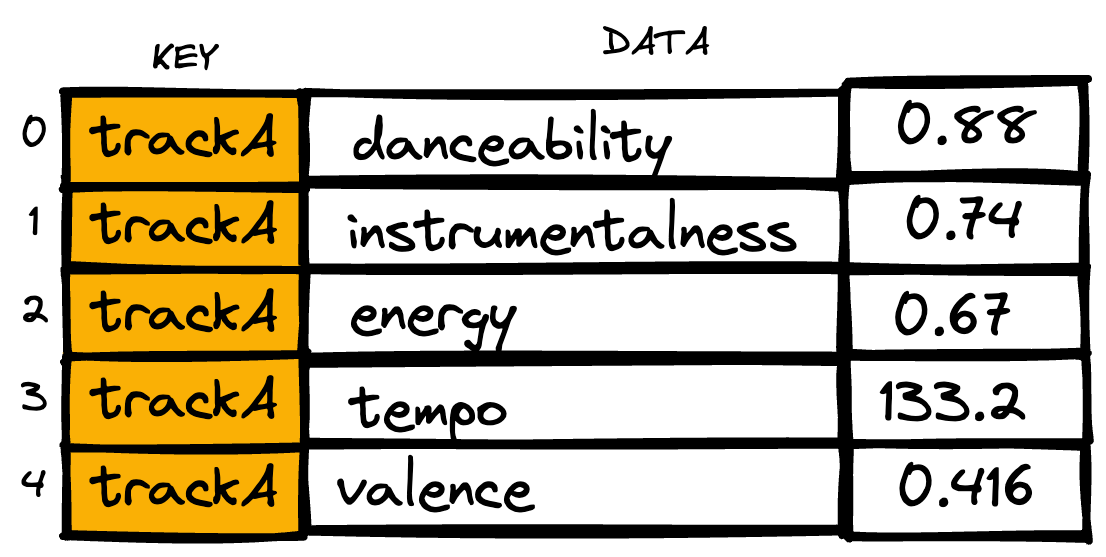
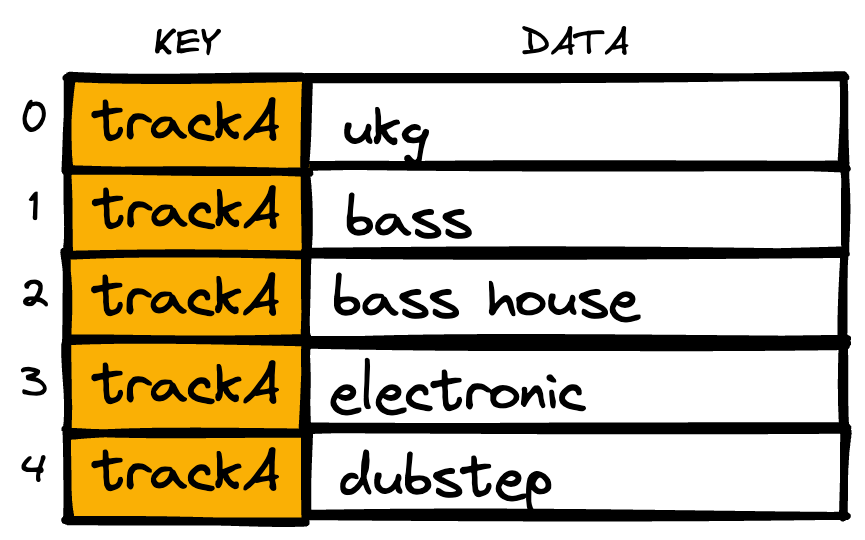
You need the text in a metadata database so that you know which terms might be used to describe music, and the associations between those terms and the metrics that quantify the instantiations of those terms in the music.
Beyond the data, you’d also need the expertise and the computing resources to develop and run generative networks that could produce music—plus the budget to pay for the people and compute. What might it take to build one?
What if we built a prompt-based music generator? #
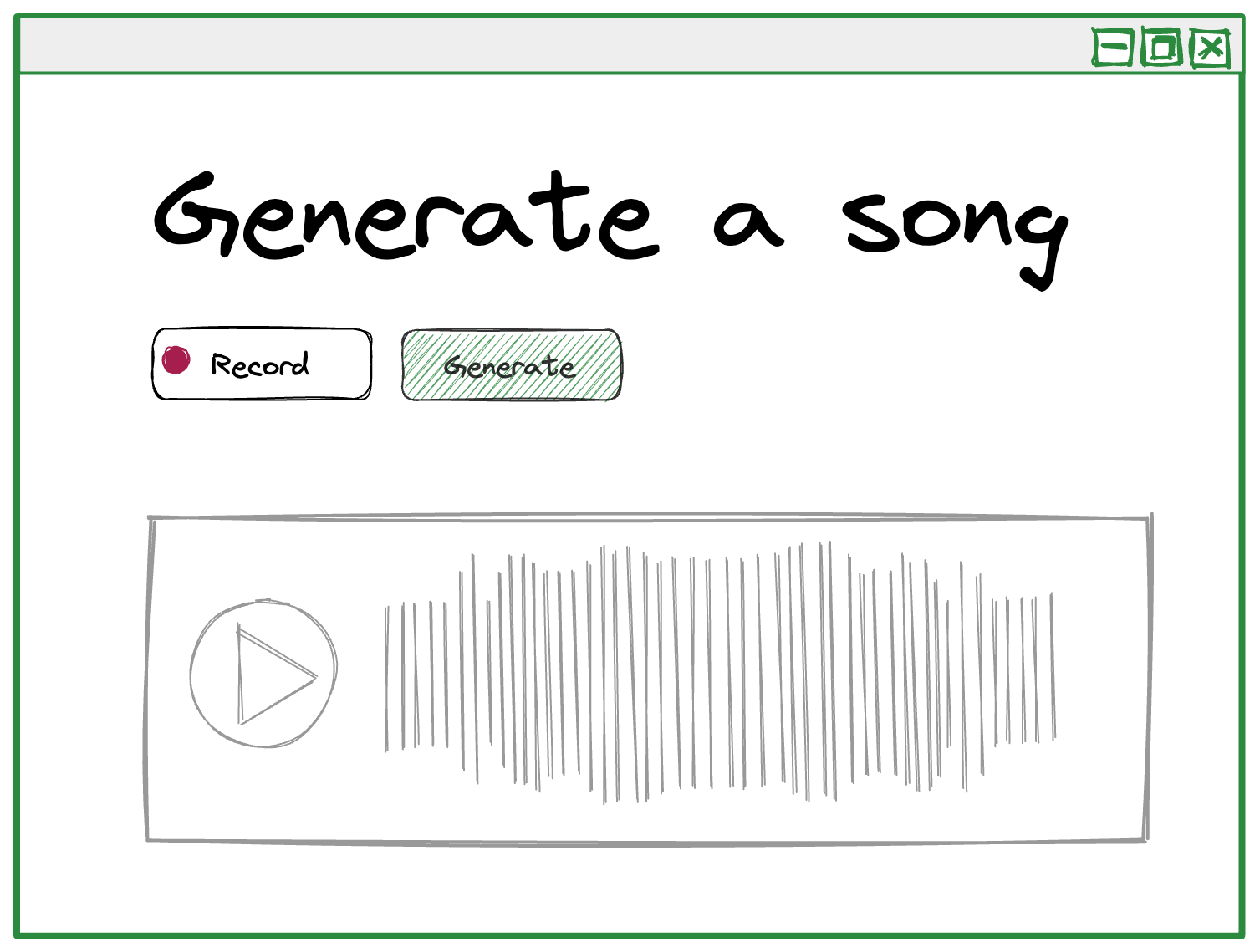
From a usability perspective, it’s pretty simple to imagine a user interface for a prompt-based music generation tool.
You write a prompt, and the service returns an audio clip created according to your prompt.

You could also add some interactive options to more granularly control options such as the length of the output, the tempo of the output, and whether or not it includes vocals.
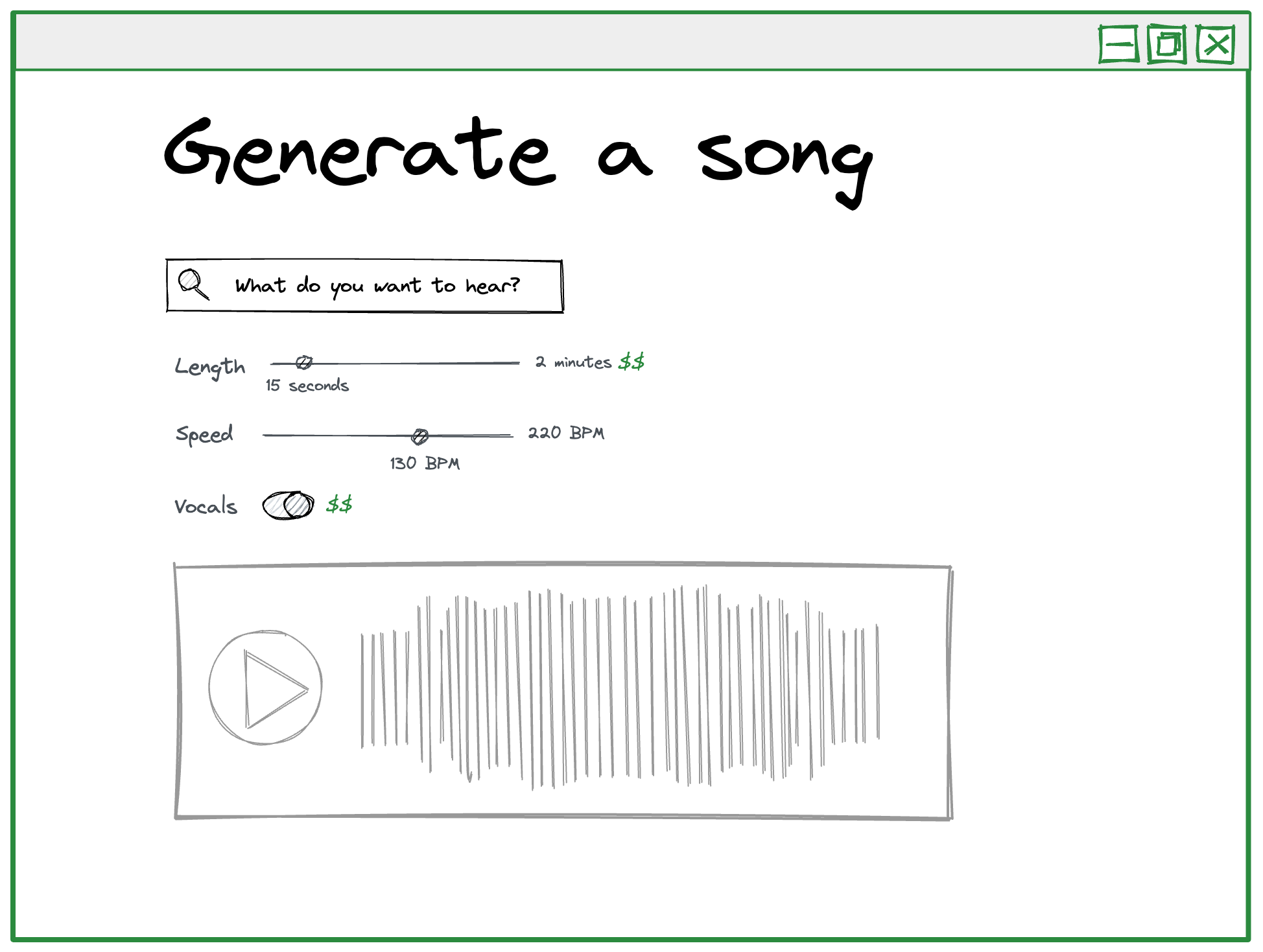
For example, if you prompt the service with “UK garage track with trumpets” and select a BPM of 130, you might get something like the following:

It’s all fine and good to design the user interface, but what about the backend infrastructure that’s actually going to do the music generation? From a technical perspective, this is where it is toughest.
There are a lot of steps involved in designing the backend infrastructure that could support generating music from a prompt like in this web interface mockup.
From my armchair machine learning understanding, here’s a high level of what those steps might involve:
- Collect or create the metadatasets.
- Clean and validate the metadatasets, or hope scale makes up for lower-quality metadata.
- Write algorithms to process the metadatasets and infer relationships between the text and quantitative metrics.
- Train generative adversarial networks, or a different type of generative machine learning framework, on the relationships between the metadatasets and on the audio correlated with the metadata.
- Review the output and make adjustments to the model training and data accordingly.
There’s a lot of complexity wrapped up in those steps, as well as a lot of time and money. Who could tackle this problem effectively?
Who could build a prompt-based music generator? #
Only a few companies have the data and machine learning capabilities to build a tool like this:
- Spotify
- Apple
- Pandora
- Gracenote (Nielsen)
All of these companies are uniquely positioned—they have explicit rights to access large swaths of recorded music, and the business cases to create detailed and accurate metadatasets for recommendation engines or for sale, as is the case with Gracenote.
Spotify has a music creation research area described as follows:
Spotify is developing novel technologies for AI-assisted music creation. We contribute to research in music modelling and music generation, both in the audio and symbolic domains, as well as developing tools for creators that use Spotify data (catalogue, stems, skip profiles) with the goal of helping artists create new musical material, styles or trends. In addition, we are defining new music creation/composition strategies adapted to the use of AI in collaboration with artists. Techniques developed range from sequence modeling (deep networks, belief propagation), audio concatenative synthesis, deep learning audio generation and many others.
But they haven’t released any music generation tools yet.
Apple, with the acquisition of Shazam, has even more layers of music metadata with the audio fingerprints stored by Shazam as well.
Google, despite having YouTube Music, only has explicit metadata about the track artist and other information and doesn’t have the extra high quality metadata layers specific to music. As such, Google would likely not be able to build something like this. However, Google does have a machine learning research organization.
Industry journal Music Business Worldwide points out that actually, the leader of AI-based music generation could be TikTok’s parent company, Bytedance. In TikTok goes on AI music-making and machine learning hiring spree, Murray Stassen covers hiring and acquisition trends by the company, making the case that they’re making focused advancements in AI-based music generation.
Outside of these companies, or the ability to license datasets from one of them, you’d have to rely on datasets like this free list of audio metadatasets, and/or the Million Song Dataset.
If one of these companies decided to build a prompt-based music generator, what challenges might they face?
Challenges with building a prompt-based music generator #
There are lots of challenges with building a prompt-based music generator. We’ve already established that it’s a technical machine learning challenge to generate music, but solving those technical challenges aren’t the only hurdles for a prompt-based music generator.
I think the biggest challenges can be organized in the following categories:
Tools exist today to generate music based on audio, just without a text-based prompt interface, so it’s possible that some of these challenges have already been solved.
Let’s start with the usability challenges specific to a text-based prompt interface.
Usability challenges #
There are some advantages to using text to prompt music generation instead of sound. If you’re tone deaf or have no sense of rhythm, you could still create some music.
It also avoids the challenge of having to record an audio file and share it with a website, but that’s a pretty trivial challenge if you’re already using the high amount of computational power necessary to locally generate, or internet bandwidth necessary to generate in the cloud and retrieve your creation.
Describing music with words is hard #
The most glaring usability challenge for a text-based prompt interface is that it’s hard to describe sound with words.
If you’ve ever tried to explain how a song sounds to someone who has never heard a song by the artist before, you realize how much ambiguous referential terminology you end up using.
You pull out phrases like “it’s like house music, but much darker” or “it has the four-on-the-floor beat but is kinda ravey at the same time” or “it’s like if Led Zeppelin did acid, but faster” until you finally succumb, pull out your phone, and play the track.
Another challenge is the type of terminology to support. As a relatively untrained music listener, I tend to describe music using phrases like the above. But if I were a songwriter or a composer, I might use specific terms like timbre, key, time signature, tempo, and others.
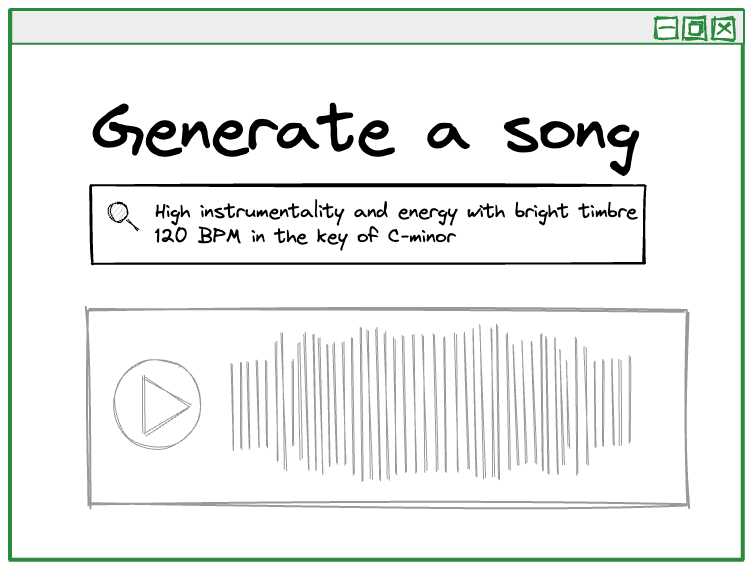
The text prompts that people use might also reference cultural figures that are unassociated with, or were briefly associated with music, such as “A pop song in the style of William Hung”.
The creators of a prompt-based music generator would need to make a product decision about whether or not to support natural language understanding (NLU) interface on top of just the features that the model was trained on, or also on a large and growing collection of cultural references that people might use to describe a sound.
Supporting cultural references would make a tool more fun to use, and perhaps offer stylistic shortcuts for people writing prompts, but would also require extensive cultural metadata to use as training data.
Verbal descriptions of music are inherently lossy. In choosing what to describe, you leave something out. I might choose to describe the vocal qualities of a track that I want to hear and neglect to mention anything about the rhythmic qualities: “bright vocals sung by a feminine voice and a guitar solo in the middle” could produce a nice track with an unintended trap-style backbeat.
Even when you’re being specific, it’s possible for your description to be lossy. For example, If you’re trying to describe Godford, you might say “they sound like The Blaze”, but that only works for someone who has listened to The Blaze (or in this case, for a model that has been trained on songs by The Blaze). Also, it only describes one specific song, not the whole vibe of the artist.
In this case, if you were to prompt a generative music model with: “Short vocal track with flute that sounds like Godford”, would the model produce a song more like The Beast or Saw You?
Words are also subjective. I was explaining to a friend that I thought HAAi’s DJ set at a recent festival was darker than I expected—but my friend didn’t know how to interpret my description. It was clear to me that a dark set meant that it was bass-heavy and grime-influenced, but darker can also mean emotionally darker, not just darker in timbre.
As an artist named Emmanuel describes in Why Dall-E will not steal my job as an illustrator, documenting his experience creating DALL-E 2 prompts:
“I forgot to mention so many details that seemed intuitive for me, like having the characters smile, looking in front of them, having the woman driving, the characters having their seatbelts on etc…”
As such, a text prompt might have to be frustratingly long to be sufficiently descriptive in order to produce a quality music sample.

Therein lies the worst part of using words to describe music, which people using text-based image generators already encounter: it’s difficult to “tune” text input in a way that produces your desired output.
It’s difficult to use text to fine-tune the output #
When we’re prompting generators, we usually have an expectation in mind of what the output will look like (or in this case, sound like). Sometimes the surprise of an unexpected result can lead to excitement or a creative inspiration, but it can also be frustrating if you’re trying to iterate on a specific concept.
Like the illustrator Emmanuel explained in his blog post, Why Dall-E will not steal my job as an illustrator, the inability to definitively specify or lock certain qualities of the output images made it difficult to imagine such a tool being used to replace storyboarding or advertising campaigns.
In order to supplant some of these usability challenges, you’d need some pretty high guardrails on the types of terminology people could use, and some suggestions for how to phrase prompts, in order to help people write useful prompts from the start.
You’d also want to give people the ability to refine a given output. If you wanted to “save” parts of the generated output and re-generate other parts, the model would need to have a high level of explainability to where you could use text to describe what needed to change on a regeneration and the model could do that.
Barring a level of interactivity with the model to selectively regenerate portions of the track, a prompt-based music generator would need to be capable of exporting the generated music as stems, or the requisite parts of the track (vocals, drums, etc.) for exploration and adjustment in a music composition and production tool like Apple Logic Pro or Ableton Live.
Music generation needs to be fast #
A final usability challenge is the time it might take to generate the output.
The OpenAI blog post section on limitations brought this challenge to my attention:
It takes approximately 9 hours to fully render one minute of audio through our models, and thus they cannot yet be used in interactive applications.
In order for a music generation tool to be usable and interactive, it would have to generate music in a few minutes at most—not 9 hours.
Quality and ethical challenges #
Generating music from a text-based prompt input is difficult to make usable, and technically challenging, but there are also quality challenges involved.
Quickly created music probably sounds bad #
Concept artist RJ Palmer, as quoted by Luke Plunkett for AI Creating ‘Art’ Is An Ethical And Copyright Nightmare, points out about AI image generation:
The unfortunate reality of this industry is that speed is favoured over quality so often that a cleaned up, ‘good enough’ AI-generated image could suffice for a lot of needs.”
For many of the commoditizable uses of music, such as background music for YouTube videos or podcasts, availability and affordability often trump quality. The types of shortcuts that easily generated music could lead to might reduce the quality of music that people encounter day-to-day.
It’s entirely likely that those types of shortcuts are already being taken when producing that kind of commercial music, but additional quality challenges are specific to machine-learning-generated music.
Generated music might all sound the same #
Christian Thorsberg3 interviewed Patricia Alessandrini, a composer, sound artist and researcher at Stanford University’s Center for Computer Research in Music and Acoustics. She pointed out this key flaw in using machine learning to generate music:
AI is better at generating content faster and copying genres, though unable to innovate new ones — a result of training their computing models, largely, using what music already exists.
We already see this with music to a certain degree, as Sean Michaels reports for The Guardian in Pop music these days: it all sounds the same, survey reveals.
Data analysis and algorithms are only adding to this effect, as Derek Thompson reports for the Atlantic in The Shazam Effect.
The increasing sameness of music can be attributed to record labels investing in “safe” artists that sound similar to acts already succeeding on the market, a desire to work with the same hot producers (Jack Antonoff, Max Martin, etc.), or even a music marketing problem where only familiar sounds get marketed in reliable markets.
Those decisions are often more visible on the top of the charts, where the network effects come together, but a machine learning model generating music would also be facing down similar problems on a smaller scale. The model would also have to produce novel sounds frequently enough to not be stale.
Much like how recommendation systems can lose listeners if they start recommending tracks that start to sound the same, if the music generating model learns a set roster of go-to sounds or beats, then the output might be more easily identifiable as artificially generated, repetitive, and uninteresting.
As v buckenham points out on Twitter4:
there is a real fear among AI researchers that the last big corpuses of human written text have already been captured. all future scrapes of the internet for text to learn from will be contaminated by machine-speak.
A prompt-based music generator could lead to a flattening of newness in mainstream music. In fact, we might already be headed there given the number of generative music tools already on the market.
Swedish artist Simon Stålenhag summarizes the cultural threat on Twitter5:
“What I don’t like about AI tech is not that it can produce brand new 70s rock hits like ‘Keep On Glowing, You Mad Jewel’ by Fink Ployd, but how it reveals that that kind of derivative, generated goo is what our new tech lords are hoping to feed us in their vision of the future”.
Further contributing to the likelihood of sameness driven by machine learning feedback loops and training data contaminated by generated music is the fact that ML engineers can’t dig their way out of this challenge by collecting even more data.
More data doesn’t lead to higher quality music #
As Dr. Timnit Gebru points out in a Twitter thread about Stable Diffusion:
“Size doesn’t guarantee diversity”6
Dr. Gebru is referring to training large language models and the fact that scraping large volumes of text from the web only captures what people have written in English on openly accessible webpages—thus ignoring anyone that writes in a different language, is unable to communicate in writing, or who chooses to communicate only in closed, unscrapeable online spaces such as WhatsApp groups or Signal chats.
Similarly, if a generative music model is trained only using the Million Songs Dataset, or even the music available to existing digital streaming providers (DSPs), then only artists with digitized music, and with the means to upload their music to DSPs and distribute it with accurate explicit metadata can be represented in a generative music model like the one I’m outlining in this post.
While it’s possible to use a diffusion model to build a music generator without extensive music metadata, a prompt-based music generator would need to use more curated datasets instead of audio files scraped off the internet in order to make the semantic connections between the text of a prompt and the expected audio features.
This means that the only music available to train a prompt-based music generator is digitized music, available on the internet, likely already licensed to DSPs, and with ample metadata available.
Legal challenges #
As long as we’re talking about indiscriminately scraping data off the internet, it’s relevant to talk about the legal challenges inherent in training and releasing a prompt-based music generator.
I’m an armchair speculator, not a lawyer. I have no legal training, so don’t take any of this for legal advice.
- Can you train a machine learning model with copyrighted music?
- Do you owe music royalties if you train a machine learning model on copyrighted music?
- What can you do with the music that you generate with such a tool?
Is it legal to train a machine learning model on copyrighted music? #
Is it legal to train models on copyrighted music? And even if it is, would you owe royalties to anyone after doing so?
Issues with copyright have already come up with prompt-based image generators. Unlike image copyright, music copyright and royalties are much more complicated.
This overview from the United States Congressional Research Service7 outlines some of the complexity:
Songwriters and recording artists are generally entitled to receive compensation for (1) reproductions, distributions, and public performances of the notes and lyrics they create (the musical works), as well as (2) reproductions, distributions, and certain digital public performances of the recorded sound of their voices combined with instruments (the sound recordings). The amount they receive, as well as their control over their music, depends on market forces, contracts between a variety of private-sector entities, and laws governing copyright and competition policy. Who pays whom, as well as who can sue whom for copyright infringement, depends in part on the mode of listening to music.
Reproduction, distribution, and performance of music are the key components of music copyright. The work, reproduction of the work, and the written score used to produce the work are each separately licensed, and royalty formulas also consider how the work was distributed—as physical media, through interactive streaming, or noninteractive streaming.
There are different methods that you can use to train machine learning models, and it’s unclear whether the different methods would be treated differently under copyright law.
For example, models like the symbolic generators described in the section on Music generation is hard would be trained with computed representations of music, where metadata describes the audio in alphanumeric terms.
Other models are trained by having a model “listen” to music, identify patterns, and attempt to recreate those patterns. This is the method that diffusion models, like Stability AI startup HarmonAI’s tool Dance Diffusion use.
It’s unclear whether these methods would be considered a form of reproduction, distribution, or performance of the music, or instead considered a form of data mining for the purposes of copyright law.
For one perspective on the copyright law, the Recording Industry Association of America (RIAA) thinks that using copyrighted music to train machine learning models is a form of copyright infringement, stating in a comment to the Office of the United States Trade Representative8 that:
To the extent these services, or their partners, are training their AI models using our members’ music, that use is unauthorized and infringes our members’ rights by making unauthorized copies of our members works.
However, the RIAA made this comment about tools that use machine learning to break apart a music track into stems, rather than music generators specifically.
Depending on the influence of the RIAA and how the use of AI-based music generation evolves in the songwriting and production portion of the music industry, determining the rights and royalties held by music generation tools could become another layer on an already-complex layer cake of music rights.

Depending on the method used to train the machine learning model, the training dataset might infringe copyright and might not. But copyright law doesn’t only exist in the United States.
The United Kingdom has a provision that makes a copyright exception9 for the following:
Text and data mining is the use of automated analytical techniques to analyse text and data for patterns, trends and other useful information. Text and data mining usually requires copying of the work to be analysed.
An exception to copyright exists which allows researchers to make copies of any copyright material for the purpose of computational analysis if they already have the right to read the work (that is, they have ‘lawful access’ to the work). This exception only permits the making of copies for the purpose of text and data mining for non-commercial research.
This exception is for non-commercial research, but the UK government plans10 to expand the copyright exception for text and data mining (TDM), concluding that:
For text and data mining, we [the Government of the UK] plan to introduce a new copyright and database exception which allows TDM for any purpose. Rights holders will still have safeguards to protect their content, including a requirement for lawful access.
It’s unclear what those safeguards and lawful access requirement will look like in practice. The UK isn’t the only country with this type of exception, however. As part of the reasoning that the UK government offers for allowing this exception for text and data mining, the document points out:
Several other countries have introduced copyright exceptions for TDM. These encourage AI development and other services to locate there. Territories with exceptions include the EU, Japan and Singapore. TDM may also be fair use under US law, depending on the facts.
There’s clearly precedent for allowing text and data mining, which can produce datasets to train machine learning models, in the EU, Japan, Singapore, and soon the UK. Expanding this exception would help the organizations I identified that could build a prompt-based music generator.
Even without explicitly permitting commercial use in copyright law, companies still find a way to use datasets created only for non-commercial use. As investigated and named by Andy Baio, AI data laundering provides a loophole:
It’s become standard practice for technology companies working with AI to commercially use datasets and models collected and trained by non-commercial research entities like universities or non-profits.
While United States copyright law might be unclear about the legality of training a machine learning model on copyrighted music, the United Kingdom, Japan, Singapore, and countries in the European Union all seem to permit it. Even without that express permission, AI data laundering is already happening to permit it anyway.
What about fair use? #
Copyright exceptions and AI data laundering help organizations circumvent copyright restrictions for training data models. When it comes to the output produced by the generative models, the concept of fair use might come into play for United States copyright cases.
Fair use is something that needs to be decided on a case-by-case basis by the courts, but the ruling in “Authors Guild v. Google” sets a helpful precedent. In this case, the court concluded that11:
The purpose of the copying is highly transformative, the public display of text is limited, and the revelations do not provide a significant market substitute for the protected aspects of the originals.
If you’re training machine learning models with copyrighted music with the intent of generating music that would then almost certainly “provide a significant market substitute” for original works of music, I’m not certain you’d succeed in court with a US copyright fair use claim for the generated music.
As a workaround, you could argue that the generated music functions as a derivative work rather than a replacement for the original work. And derivatives aren’t unique to generated music.
Claire Evans, writer and member of YACHT, points out in an interview12 that music creation without prompt-based music generators is also often derivative:
“That’s something that artists are already doing in the studio in a much more informal and sloppy way,” Evans said. “You sit down to write a song and you’re like, I want a Fall bass line and a B-52’s melody, and I want it to sound like it came from London in 1977.”
But while visual artists might not be able to do much about a lookalike image, musical artists already have copyright protections for various types of derivatives, including direct samples of their work as well as remaking part of a song, called interpolation.
This complexity means that any “soundalike” clips generated by prompt-based generative model, even if you’re not knowingly, intentionally, or actually sampling a musician’s work, you might owe an interpolation credit to some entity.
Unlike Taylor Swift, who filed a motion in a copyright lawsuit claiming that she “had never heard the song Playas Gon’ Play and had never heard of that song or the group 3LW”, music created by a prompt-based music generator can’t use that defense unless the track being infringed on was not part of the original or subsequent training data for the generative model.
This risk is confirmed by Kyle Worrall, “a Ph.D. student at the University of York in the U.K. studying the musical applications of machine learning” in an interview with Kyle Wiggers and Amanda Silberling for TechCrunch12 about the originality of generated output:
“There is little work into establishing how original the output of generative algorithms are, so the use of generative music in advertisements and other projects still runs the risk of accidentally infringing on copyright and as such damaging the property,” Worrall said. “This area needs to be further researched.”
So while the use of copyrighted music to train a machine learning model might be protected by a copyright exception, and possibly even fair use, the generated music produced by the model could still infringe on copyright and require royalties to be paid.
What can you legally do with generated music? #
Given this copyright context, it matters what you do with the output from a prompt-based music generator.
As pointed out in the report from the United States Congressional Research Service7:
Songwriters and recording artists are generally entitled to receive compensation for (1) reproductions, distributions, and public performances of the notes and lyrics they create (the musical works), as well as (2) reproductions, distributions, and certain digital public performances of the recorded sound of their voices combined with instruments (the sound recordings).
If you generate music that might infringe on the copyright of songwriters and recording artists, you might owe royalties if you reproduce, distribute, or perform that music (live, on the radio, or through a streaming service, to name a few examples).
The main goal of using a prompt-based music generator is to create royalty-free music for specific use cases, but copyright infringement risks might mean you owe royalties anyway.
If you wanted to hedge those copyright infringement risks by copyrighting the generated music yourself, then you encounter more legal challenges.
Royalties can be allocated to songwriters, producers, vocalists, musicians, and others involved in making a track. If some or part of the track is the result of a prompt-based music generator, what happens to that share of the royalties?
Furthermore, to whom would those royalties get paid out?
- The people that trained the machine learning model that generated the music?
- The people that wrote the machine learning model?
- The people that prompted the model to generate that specific track?
It probably doesn’t matter because it’s likely that using a prompt-based music generator (or even the existing music generation tools today) could prevent you from copyrighting tracks created that way.
In the United Kingdom, copyright law protects generated works for 50 years, with the authorship described as follows13:
In the case of a literary, dramatic, musical or artistic work which is computer generated, the author shall be taken to be the person by whom the arrangements necessary for the creation of the work are undertaken.
The same effort that resulted in plans to expand the copyright exception to text and data mining made no changes to this law, asserting10:
For computer-generated works, we plan no changes to the law. There is no evidence at present that protection for CGWs is harmful, and the use of AI is still in its early stages.
So you can copyright your generated music tracks in the UK. In the United States, however, it’s more complicated.
Luke Plunkett in AI Creating ‘Art’ Is An Ethical And Copyright Nightmare identified a copyright case that is likely to have ramifications for music copyright in the United States if music generation becomes more common. To quote his article:
In February, the US Copyright Office “refused to grant a copyright” for a piece of art made by AI, saying that “human authorship is a prerequisite to copyright protection”. That case is now being appealed to a federal court, however, because the AI’s creator thinks that, having programmed the machine, he should be able to claim copyright over the works it produces. Even when a decision is ultimately reached in this case, it will take a lot more time and cases for a firmer legal consensus to form around the subject.
But what is that work the AI’s creator is claiming, if not simply a casserole made from art created by actual human artists, who are not being paid or even credited for their contributions?
Therein lies the challenge with granting copyright on “computer-generated works”—which person has the right to claim authorship? You might not be able to copyright the tracks you create with a prompt-based music generator at all.
There’s a lot of copyright law to untangle for prompt-based music generators, from the training and development perspective, as well as the distribution, copyright infringement risks, and challenges with getting your own copyright for the tracks if you want to.
The legal challenges are perhaps the most complex, but not the only challenges facing anyone trying to build a prompt-based music generator. Given that, will we see one at all?
Will we see a prompt-based music generator? #
Given the market opportunity for generated music and the long list of challenges, will we see a prompt-based music generator?
It’s tough to say. If DALL-E 2 and Stable Diffusion survive past the “hype cycle” and are consistently used, then we’ll almost certainly see prompt-based music generators.
Getting high quality music from a prompt-based music generator is the biggest challenge.
To get there, two technical advancements are necessary:
- Developing the machine learning methods necessary to generate high-quality music based on an arbitrary output.
- Evolving the song-characteristic prompt used by many music generator tools already to use full natural language, cultural references and all.
The existing machine learning capabilities can do a lot, but we might end up with new types of training (like diffusion models) or elaborate iterations of training (like the “conditioning” that OpenAI used with Jukebox) before we get music generators that can emulate song structure.
If the machine learning methods get solved before the natural language prompt is wired up to audio generation, we might end up with an audio-based prompt before a text-based prompt.
Most people are musical to a degree, and there might be more novelty in humming a ditty into your laptop microphone and getting a 15 second audio clip than there is in entering a string of text into a text box and trying to get it to output something that sounds like what you can hear in your head.
With that audio-based prompt, you can also avoid many of the usability challenges with using text to describe music.
It’s tough to say how soon we’ll see a prompt-based music generator. While HarmonAI is making progress with Dance Diffusion, any pre-trained models they can release are limited by the availability and quality of music datasets.
Even if we do see a prompt-based music generator, it might not be consumer-facing. For now, it seems like companies that might have a market advantage developing prompt-based music generation are investing elsewhere.
The companies that I identified in Who could build a prompt-based music generator all use machine learning extensively, but for applications of ML that make tasks easier, increase engagement, and make the companies more money.
For example, the following ML applications:
- Adding computer vision capabilities to photos at Apple
- Improving music track isolation for Shazam at Apple
- Separating tracks into stems using machine learning at Spotify
- Improving podcast discovery at Spotify
- Improving recommendations and personalization for Radio at Pandora
Out of any of these, Spotify is the most likely to invest in music generation.
In 2017, Spotify hired François Pachet to direct “the Spotify Creator Technology Research Lab, where he designs the next generation of AI-based tools for musicians.”, as reported by Music Business Worldwide.
We could see some more AI-based tooling from Spotify’s music creation research lab, but given Spotify’s increasing investment in podcasts, I think it’s most likely that the first iteration of a music generation tool would be for internal use to support podcast creators with the type of commercialized audio that functions well as intro, outro, and background music in podcasts.
What might we see before a prompt-based music generator? #
We’ll continue to see evolutions of the music generation tools already on the market. Those exist as collaborators to music producers, songwriters, and other musical artists.
Perhaps we’ll see SoundCloud release some machine learning-based tooling for musicians innovating on their service, or tools exclusive to Warner Music Group to help their artists iterate faster on their songs—an increasing emphasis on producing music efficiently while also claiming to retain some elements of creativity.
Whether or not we see these changes at major labels or services that support entry-level artists depends on who is in power at these companies, and how much they favor the organic creative experience over an extended commoditization of media and music to maximize shareholder value.
If we do see a prompt-based music generator soon, especially one that doesn’t work very well, the text prompt data will be valuable for music industry players to evaluate. Record labels might want to analyze the types of prompts entered into the service, especially in early adoption stages before people learn the “prompt engineering tricks” to produce specific sounds from the model, rather than describe what they want to hear.
The text prompt data could provide inspiration or guidance to the agents and others at a record label trying to identify the next big sound, or surface an underserved niche in the music market.
Music generation generally also offers the possibility of generating an audio clip to test an idea or a music market by using that clip in a TikTok or an Instagram Reel. If the video goes viral, then you could attempt to generate a full track, or seek out artists with that sound to produce a full track inspired by the audio clip.
Of course, virality doesn’t necessarily lead to success, as the TikTok artists profiled in the Vox Earworm video with The Pudding, We tracked what happens after TikTok songs go viral reveal, so this isn’t a foolproof method of testing the market, but it is a way to try to shortcut finding the next big hit.
No matter what happens with music generation tools, musicians aren’t going anywhere. As musician and YouTube personality Adam Neely points out in his video Will AI replace human musicians? | Q+A, technology replacing musicians has been a fear for decades—but we’ll all keep making music nonetheless.

Thanks to EI d’AU, Youri Tjang, and Aleksandra Lazovic for your Excalidraw libraries, as well as Clay and Thomas in Discord for providing helpful feedback on earlier drafts of this post.
-
The current version of capitalism says yes. ↩︎
-
Linked by the Weights and Biases article, A Gentle Introduction to Dance Diffusion. ↩︎
-
Reporting for Grid in The future of AI in music is now. Artificial Intelligence was in the music industry long before FN Meka, linked to me by the Platform & Stream newsletter. ↩︎
-
Referenced by Luke Plunkett in AI Creating ‘Art’ Is An Ethical And Copyright Nightmare ↩︎
-
Gebru is referencing her paper, On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? with Emily Bender, Angelina McMillan-Major, and Shmargaret Schmitchell. ↩︎
-
Quote from page 4 of version 22 of report R43984 from the Congressional Research Service entitled “Money for Something: Music Licensing in the 21st Century”. ↩︎ ↩︎
-
Quote from Page 12 and 13 of RIAA Submission to Comment Request for the 2022 Review of Notorious Markets for Counterfeiting and Piracy, uploaded and shared in an article by Ernesto Van der Sar on Torrentfreak titled RIAA Flags ‘Artificial Intelligence’ Music Mixer as Emerging Copyright Threat. The comment request the RIAA is responding to is 2022 Review of Notorious Markets for Counterfeiting and Piracy: Comment Request. ↩︎
-
Text and data mining for non-commercial research on the Exceptions to Copyright page for GOV.UK. I found out about this exception in UK copyright thanks to this tweet by Kevin Brennan MP. ↩︎
-
Artificial Intelligence and Intellectual Property: copyright and patents: Government response to consultation. ↩︎ ↩︎
-
Page 230 of Authors Guild v. Google, Inc., 804 F.3d 202 (2015) decision by the United States Court of Appeals for the Second Circuit. Thanks to Andy Baio in his blog post about copyright and AI tools, With questionable copyright claim, Jay-Z orders deepfake audio parodies off YouTube, for transcribing the video by the anonymous creator of Vocal Synthesis, Barack Obama and Donald Trump read a special message from this channel’s creator (Speech Synthesis), which led me to discover this case. ↩︎
-
Interviewed by Kyle Wiggers and Amanda Silberling for TechCrunch for AI music generators could be a boon for artists — but also problematic. ↩︎ ↩︎
-
Page 32 of the Copyright, Designs and Patents Act 1988, in the PDF linked to from that page. ↩︎