Don't replace your user community with an LLM-based chatbot
There’s been some discussion about the challenges of implementing LLMs, but I haven’t seen any comments about the effect a large language model-based chatbot could have on a company’s user community.
Implementing an LLM-based chatbot seems like an excellent way to do two important things:
- Help people find information about your product
- Collect data about the information people want about your product
Using a technology-only solution to achieve those goals seems like the ultimate, low-cost way to grow product usage and awareness. But there’s another way—building a strong user community.
Like LLM-based chatbots, user communities aren’t free—they require investments in tools and people to help cultivate the community with in-person user groups, dedicated forums, and/or chat apps like Discord or Slack. Some companies neglect them, leaving the conversations to occur only in the chat apps of related products, or social media.
But even a weak user community offers more benefits than an LLM-based chatbot. An article from Zendesk points out the key benefits of user communities:
Brand loyalty #
The brand loyalty component is what makes a user community, and your customer base, more resilient (and yes, scalable). You might turn to an LLM-based chatbot to scale customer support or deflect more support cases, but a user community can do that too, with the added bonus of building personal connections along the way.
When your customers interact with each other, and with employees of your company, they build relationships—and those relationships keep people returning to user community hubs like chat communities on Slack or Discord, forums like StackOverflow, or even subreddits on Reddit. Personal relationships motivate people to attend conferences that are focused on your product or service, but are also social occasions.
If your product is good, the personal connections that customers build with each other and with the people building your product can also build loyalty to your product.
Self-service support #
It might seem like LLM-based chatbots can offer self-service support—and they can, to a point. It all depends on the training data and the prompted context that the chatbots have access to.
Many LLM-based chatbot implementations rely solely on the product documentation content to answer customer questions—but documentation doesn’t contain instructions for every possible use case, but rather the most common ones (it would be overwhelming to read and maintain otherwise).
For obscure and specific use cases, asking a question in a community forum can often provide a more helpful interaction. For cases where a customer has a mental model mismatch about how the product works, interacting in a chat with actual people who can ask thoughtful follow-up questions can offer a more fruitful interaction than an LLM-based chatbot that can only provide output, and no follow-up questions.
Take this question asked on StackOverflow, ostensibly about ChatGPT token limits:
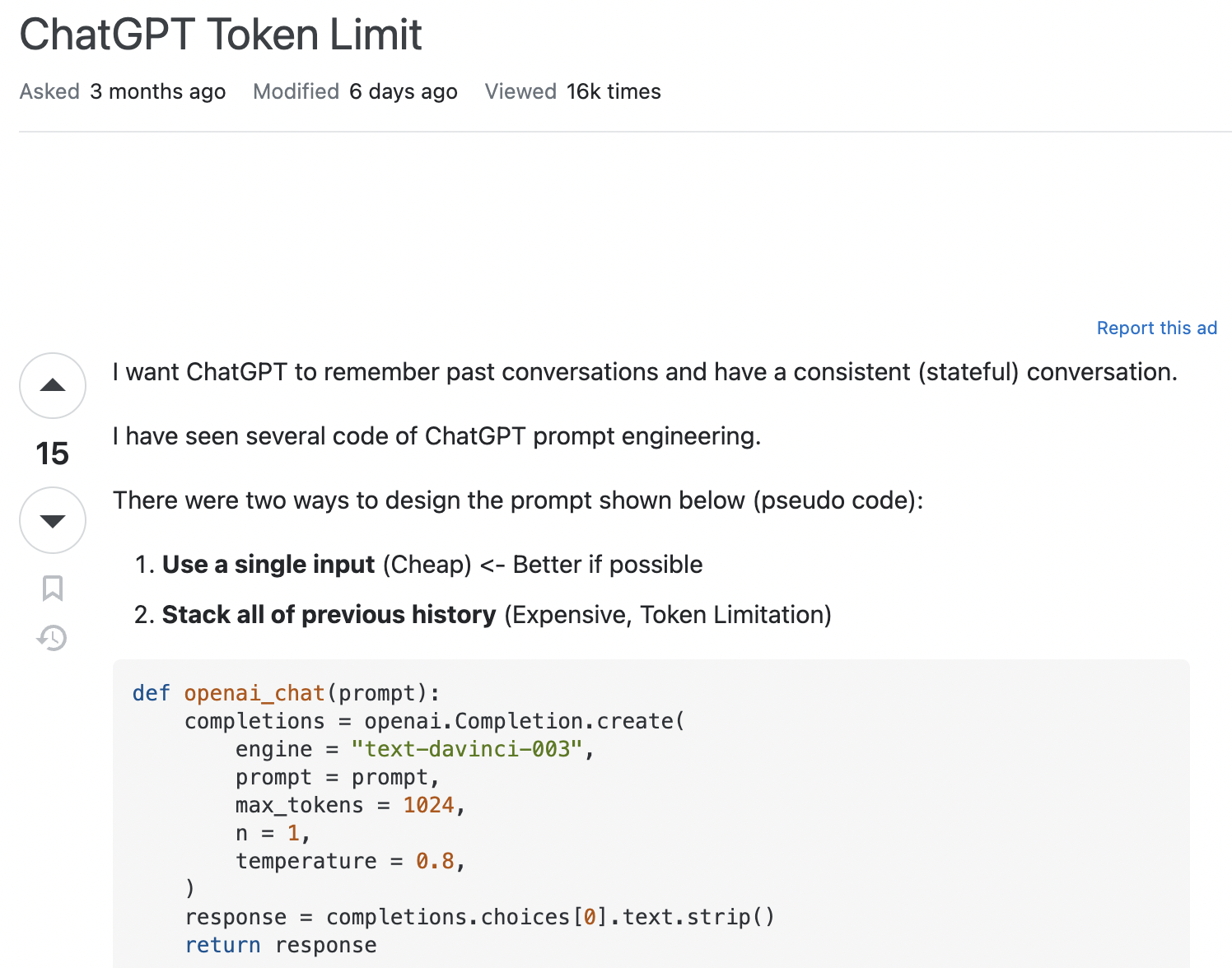
The top answer takes the time to educate the question author about the difference between ChatGPT and the GPT model that the question author is actually using:

In this case, the language in the question made it clear that the author had an imperfect understanding of the problem space they were working with, which led to a different type of answer.
The response from an LLM can’t reframe and recontextualize the problem in this way. If you’re trying to find information about something but struggling to articulate your question, only a person can help you.
With enough quality training data, such as from a carefully curated and labeled dataset from an internally maintained community forum of questions and answers, an LLM-based chatbot might be able to mimic this clarifying mental model behavior, but it would still be limited.
Social proof and brand advocacy #
This strong user community can serve as an informal sales force talking about your product’s capabilities on websites that persist the content, like StackOverflow or Reddit, that can help drive new customers and new business. Meanwhile, an LLM-based chatbot can only help customers that find the tool and ask questions that they know they have. There’s no passive discovery.
Social proof, or the recommendation of your product by trusted experts in the field, is a valuable source of new customers (and reinforcement of existing customers) — one that you can’t buy your way into, or paper your way into with content marketing.
As one example, a question on r/Splunk about whether Splunk is worth the cost yielded this response:

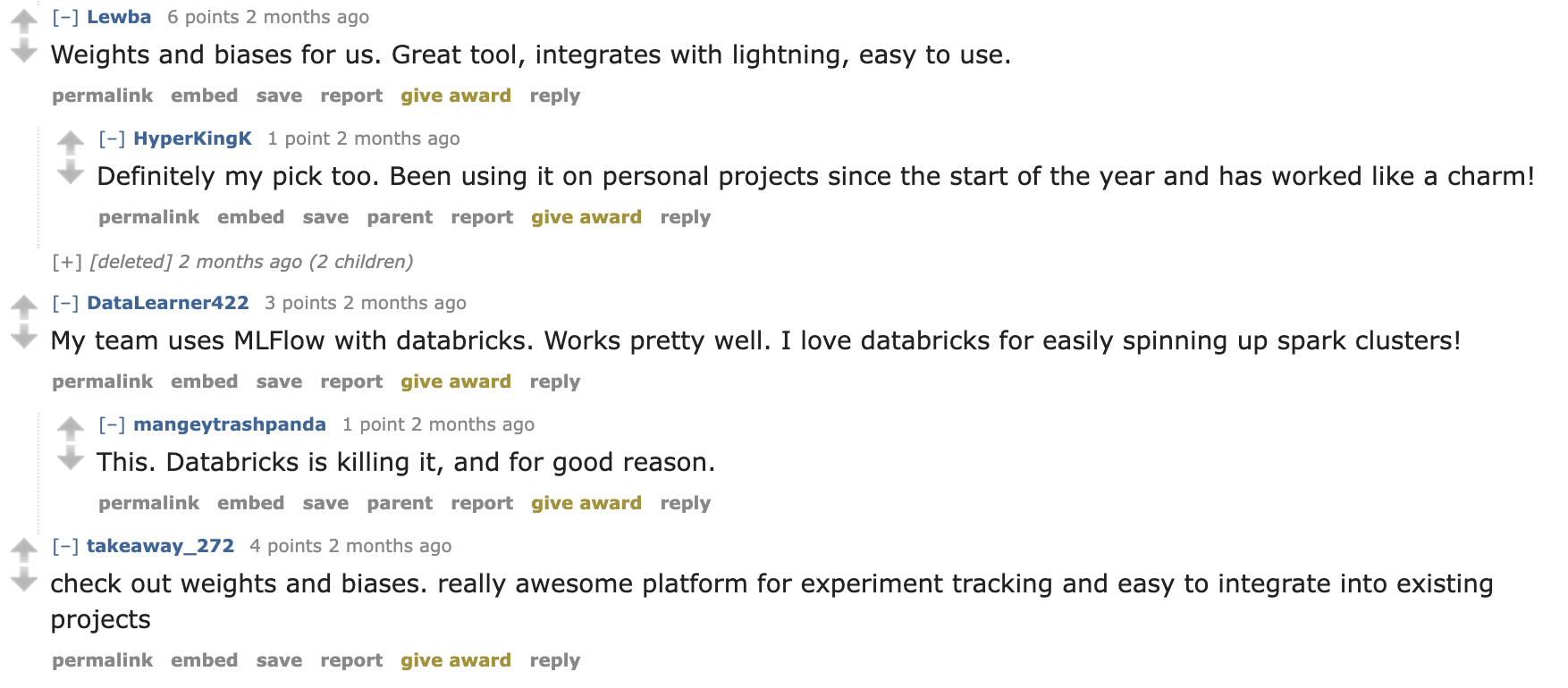
As another example, a question on r/datascience about people’s favorite experiment tracking tools provides a lot of recommendations for someone that might want to start tracking machine learning experiments but isn’t sure where to start.
If you’re idly looking for a tool to use but aren’t even sure of your requirements and stumble across this conversation, you might realize that you also need a tool that integrates with existing projects and look further at Weights & Biases:
As an employee of one of these companies, you can respond to these questions, but it’s less trustworthy than when a real customer responds with their experiences and opinions.
Customer insights #
The data you get from a LLM-based chatbot can provide customer insights—rich information about what people want to know about your product, or what people are struggling to find information about, or the problems that they’re trying to solve. If you require users of the chatbot to log in (as Netlify does), then you also gather information about who the people are (although you limit the users to existing, rather than including prospective, customers).
When you build a user community, it’s easier to get quality product feedback from customers that you understand. You can collect feedback about your product or your documentation and build relationships with trusted partners as well as average customers that might be too “small potatoes” to garner special concessions from the product or support teams, but provide a dedicated user base that can expand their usage of your product.
Not only that, but you can get immediate interactive feedback if you interact with your community in a chat app like Discord or Slack. Rather than a data dump that you might need to make time to review and analyze from an LLM-based chatbot, you can engage directly with your customers where they are, and learn more about their use cases in the moment.
While you clearly get customer insights from an LLM-based chatbot, you miss out on most of the benefits of a user community to your business.
Don’t hyperfixate on chatbots #
If the community discussions and Q&As about your product get routed largely or entirely to an interaction with a Large Language Model, you have lots of data but no true user community. You might find yourself (and your customers will too) staring at comments stored in a database instead of talking to people.
Without the personal connections crafted in a user community, you miss out on direct customer feedback sourced through genuine conversations—ones where you can ask questions too—and lose an opportunity to build brand loyalty. No one feels loyal to a chatbot.
A chatbot can offer self-service support to customers, but only to those that are already asking questions—and only if the answers to those questions are already written down.
If you implement an LLM-based chatbot at your company, don’t do so at the expense of your user community. Otherwise, the longevity and quality of your product will suffer.